YOLOv4,v5,X理解
YOLOv4
YOLOv4是在YOLOv3的基础上进行了一些改进,但是整个流程依旧是YOLOv3,比如正负样本的划分、忽略样本等等。
其中添加的改进主要有如下几点:
- 跨阶段局部网络(Cross-Stage-Partial, CSP)作为主干网络进行特征提取
- Mish激活函数(backbone)和Leaky ReLU(neck)
- Mosaic数据增强、MixUP数据增强
- 添加注意力机制模块
- CIoU作为边框回归损失
- 在neck中添加空间金字塔池化(Spatial Pyramid Pooling, SPP)提升感受野
- 在原先YOLOv3 neck的特征金字塔网络(Feature Pyramid Netword, FPN)的基础上改进为路径聚合网络(Path Aggregation Network, PAN)
YOLOv5
YOLOv5并无论文,我以开源代码中的实现来说明(version 5.0)。
新的正样本选择机制
网络输出部分xywh的偏移计算公式发生改动,现在xywh都会经过sigmoid归一化。
- 网络输出xy偏移公式:$pred_x = t_x*2-0.5+grid_x$
- 网络输出wh偏移公式:$pred_w = (t_w*2)^{2}*anchor_w$
这样设计xy的原因是,YOLOv3如果中心点在极边缘,那么网络的输出需要是个比较大的值,才能通过sigmoid得到极边缘的位置,这不好学习,改进的方法则可以消除这个问题。
这样设计wh的原因是,指数不好控制,容易训练不稳定
对于每个gt,会先计算它与9个锚框的宽与宽之比,高与高之比,以及倒数;结果会得到每一个gt与9个锚框的4个比值,选择4个比值的最大值作为代表值,代表值比值因子在一定范围内(如4)的先验框作为负责预测该目标的先验框(因此可能会有多个先验框负责预测该gt)。
进一步,正样本会根据中心点的具体位置,会添加四个角的额外两个特征点来预测,一共每个目标有三个位置的对应大小的先验框来负责预测(可能会有相同大小的先验框的不同位置都负责预测该gt)。当然,过程会有可能某个先验框负责多个gt的预测的矛盾产生,但是不用担心,会根据代表值最低匹配原则来确认它到底负责哪一个gt
总的来说可能会有多个尺度的多个位置负责预测某个目标,相比较于YOLOv3、YOLOv4,大大提升了正样本数量
其他改动
- Focus模块,主干网络起始以Focus结构降低特征图宽高,不过该结构在最新版已经弃用
- 网络全部采用SiLU激活函数
- CSPLayer相较于YOLOv4发生一点点改动,减少一个卷积模组
- 将SPP模块放入到主干网络最后一部分(后续版本提出SPPF,性能优秀)
- neck部分的卷积堆叠用CSPLayer替代,并修改部分通道改变情况
- 通过尺度因子:通道深度、残差块层数,来定义网络从而划分s、m、l、x大小不同网络
YOLOX
YOLOX的整体网络架构基本上和YOLOv5一致(原论文大多实验也是基于YOLOv3),所以该网络主要创新是在解耦头以及正样本选择方面。
正样本选择策略(SimOTA)
值得一提的是预测xywz的偏移,不需要经过sigmoid归一化
- 网络输出xy偏移公式:$pred_x = t_x+grid_x$
- 网络输出wh便宜公式:$pred_w = e^{t_w}$
具体的正样本(特征点)选取规则:
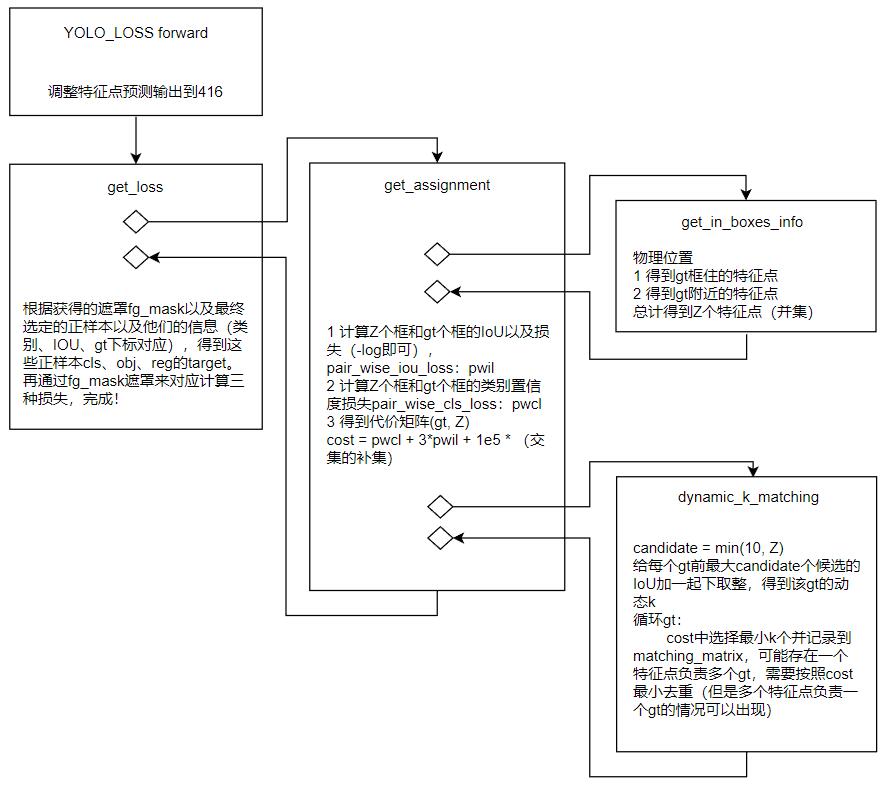
其他改动
- 计算损失时,类别损失标签不是1,是该特征点对于的预测框与对应gt的IoU
- anchor-free:输出分叉,然后结果堆叠就行了
- Decoupled Head,解耦头预测