YOLOv3源码理解
0 主干网络
YOLOv3采用DarkNet-53网络,结构如下图(DarkNet-53预训练于ImageNet,由于是1000类的分类,所以网络最后输出经过全连接层。但是目标检测不需要那个全连接层,因此实际上只使用了“DarkNet-52”,共52层卷积层):
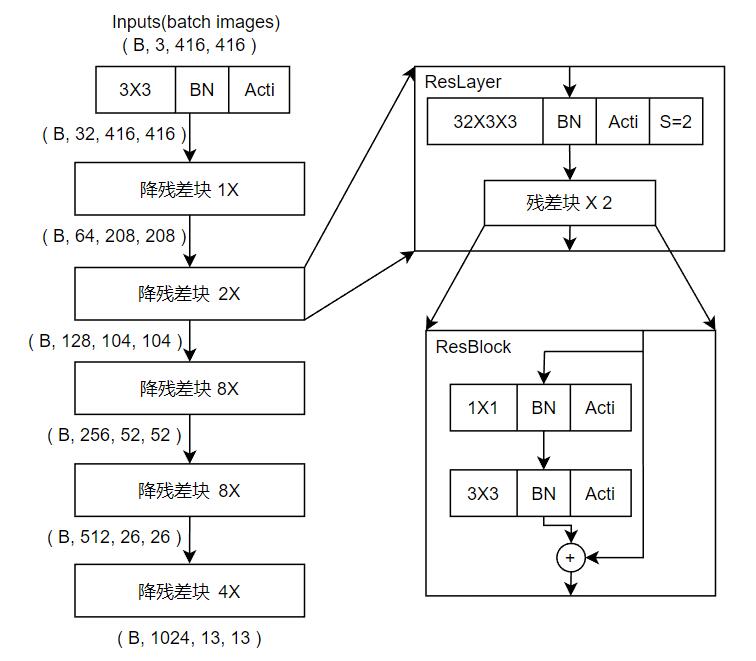
- BN为批归一化层,Acti为激活函数,YOLOv3采用LeakyReLU
- 输入批次经过一个3X3卷积改变通道数为32,然后经过5个降残差块。每个降残差块包含一次步幅为2的3X3卷积加上一系列残差块。每个残差块包含一次1X1卷积降低通道数,再经过一次3X3卷积提升通道数,最后和残差边进行连接。
- 整体主干网络清晰,每经过一个降残差块,通道数翻倍,特征图宽高减半。
1 预测分支网络
下图是YOLOv3的预测分支网络部分,是一个典型的特征金字塔结构。最后的输出通道75是假设采用VOC数据集进行20个类别的检测,因此输出的75代表3*(4+1+20),3代表每个特征点3个先验框;4代表先验框x、y的偏移量以及宽高的伸缩量;1代表该先验框包含目标的置信度;20代表该数据集类别个数。
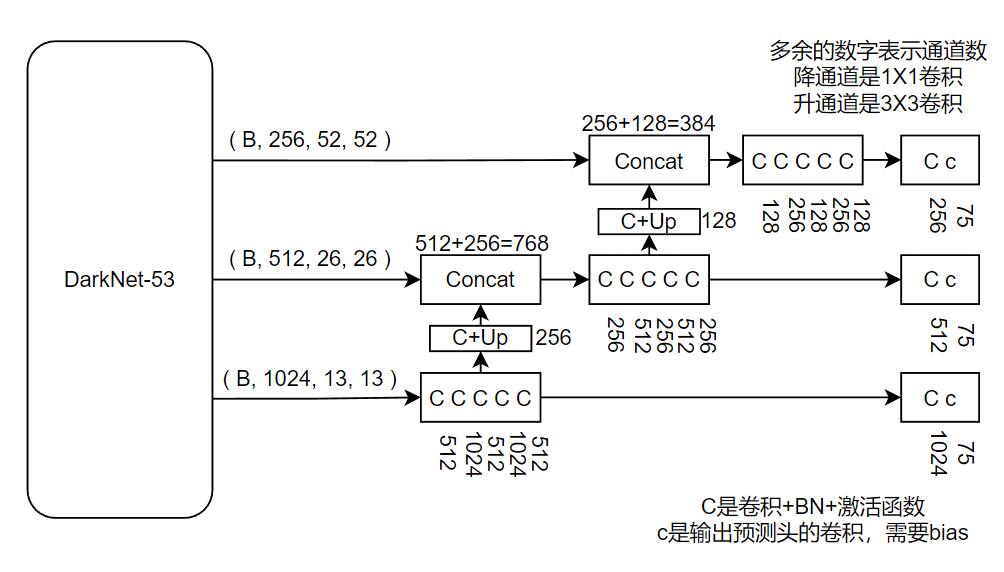
2 数据加载
- 图片会被进行各种图像增强、添加灰条等操作,最终大小为
(416,416),值归一化到0~1,形状为(B, 3, 416, 416) - 标签会被归一化
0~1(从数据集[左上右下]转换为[中心宽高]),形状为list[(GT, 4)...B个]
3 训练网络
- 网络前向传播会获得一个包含三元素的元组:
((bs,75,13,13),(bs,75,26,26),(bs,75,52,52)),代表网络三个层的输出 - 依次计算每个层的损失,相加之后进行反向传播
3.1 输出层的解码
以(bs,75,13,13)为例,view到(bs,3,13,13,25),随后通过其中包含的信息结合给该层分配的三个先验框的宽高,可以得到预测框的结果。
(..., 0:2)执行sigmoid获得该层先验框的偏移(..., 2:4)不执行任何操作,之后用于宽高的缩放(..., 4)执行sigmoid获得包含物体的置信度(..., 5:)执行sigmoid获得被认为是每个类别的概率
3.2 正负样本
- 批次里的每个图片都会单独循环处理:将这些真实框与9个先验框做IOU,从而确定每个真实框由哪个大小的先验框负责。确认后,再根据真实框的中心位置,确认属于哪个特征点负责,最终即可确认由哪一个先验框(确定了哪一层)的哪个特征图(该层的哪个格子)负责,正样本既定。
- 按理说,其他未分配真实框的预测框都是负样本,有
(13*13+26*26+52*52)*3 - 9 = 10647 - 9 = 10638个负样本。但是作者考虑到,某些本不负责预测目标框的预测框,如果其IOU与该目标比较重合(例如大于0.5),则不能将其作为负样本,应该忽略之。因此实际的负样本应该是小于该值的。
3.3 损失函数计算
- YOLOv3包含三个损失:边框回归损失、目标置信度损失、类别损失
- 对于正样本,三项损失都要计算:
- 其中边框回归损失可以采用
MSELoss、BCELoss、或者各类的IOU损失,例如DIOU, GIOU, CIOU - 目标置信度损失直接采用
BCELoss,可以选择和Focal Loss形式结合 - 类别损失直接采用
BCELoss
- 其中边框回归损失可以采用
- 对于负样本,只计算目标置信度损失,直接采用
BCELoss,可以选择和Focal Loss形式结合。注意,当选择Focal Loss形式时,该项损失的权重系数要重新配置,一般要增大很多。而且训练结束后的预测的置信度*类别可能会降低,因为只学习难的,简单易判的往往损失权值极地,基本不学习,导致这种现象产生。
4 预测网络
- 转RGB、调整形状、添加灰条(可选)、归一化0~1、添加批次通道,最终形状:
(1,3,416,416) - 送入网络得到结果,一个包含三元素的元组:
((1,75,13,13),(1,75,26,26),(1,75,52,52)) - 将结果解码:根据预测结果和先验框宽高,得到一个包含三元素的列表:
[(1, 3*13*13, 25), (1, 3*26*26, 25), (1, 3*52*52, 25)],最终合并为单个张量:(1, 10647, 25)。其中的值都被归一化为0~1了 - 将数据转换为
(10647, 7)代表xmin, ymin, xmax, ymax, conf, class_conf, class_pred,按照(..., 4)*(..., 5) > threshold获得保留的预测框 - 按照每个类别,分别执行非极大值抑制,最后收集保留的这些预测框
- 将预测框按照之前图像预处理,进行反向操作(其中为方便操作,将之前的7属性的坐标部分进行颠倒,现在为
ymin, xmin, ymax, xmax, conf, class_conf, class_pred),可以理解为top, left, bottom, right