我们有一堆数据,希望能够支持快速的插入、删除、查询以及范围查询 我们都知道数组进行排序后,可以通过二分查找的方式快速定位数据,时间复杂度是$O(LogN)$,但是如果数组经常发生插入、删除操作,就需要进行大量平移,时间复杂度是$O(N)$。 那用平衡树呢?AVL树、红黑树都是经过深度优化的动态数据结构,他们的插入删除查找都可以在$O(LogN)$的时间内完成,但是他们实现起来较为复杂,且对于范围查询,还需要进行中序遍历,但至少比数组好多了。 那链表呢,链表的插入删除是很方便,但关键查询呢,它能进行二分查找吗?链表无法随机访问,怎么二分?很显然,直接对普通链表进行二分查找是困难的。1990年,Pugh发表论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》,创造性的提出了自己的解决方案:”如果不能在节点间跳跃,那就建造可以跳跃的桥梁吧!”,跳跃表(SkipList)正式被提出。 跳跃表是一种概率性的有序数据结构,通过建立多级索引来加速查找,可以看作是在链表基础上加了“快速通道”,变相了实现对链表的二分查找,并且,范围查找也能够很轻易的完成,只要找到目标,就可以沿着链条依次访问。 游戏里排行榜一般是采用Redis Sorted Set,它在数据规模较大时的底层数据结构就是跳跃表+哈希表。
// 获取前N名(分数从高到低) public List<T> GetTopN(int n) { if (n <= 0) returnnew List<T>(); if (n > _count) n = _count;
List<T> result = new List<T>(); SkipListNode current = _tail;
// 从尾部向前遍历 for (int i = 0; i < n && current != null; i++) { result.Add(current.Value); current = current.Backward; }
return result; }
// 获取分数范围内的元素(利用跳跃表特性,O(log N + M)) publicList<T> GetRangeByScore(double minScore, double maxScore) { if (minScore > maxScore) returnnew List<T>();
List<T> result = new(); SkipListNode current = _header;
// 步骤1:使用高层索引快速定位到第一个 >= minScore 的节点 (O(log N)) for (int i = _level - 1; i >= 0; i--) { while (current.Forward[i] != null && current.Forward[i].Score < minScore) { current = current.Forward[i]; } }
// 现在 current 是最后一个 < minScore 的节点,下一个就是第一个 >= minScore 的节点 current = current.Forward[0];
// 步骤2:从定位点开始顺序遍历,直到超过 maxScore (O(M)) while (current != null && current.Score <= maxScore) { result.Add(current.Value); current = current.Forward[0]; }
return result; }
public List<T> GetRangeByRank(int start, int end) { var ret = new List<T>(); if (start > end) return ret; if (start <= 0) start = 1; if (end > _count) end = _count; var rank = _count - start + 1; var current = _header; for (int i = _level - 1; i >= 0; i--) { while (current.Forward[i] != null && current.Span[i] <= rank) { rank -= current.Span[i]; current = current.Forward[i]; }
if (rank == 0) break; }
var cnt = end - start + 1; while (cnt-- > 0 && current != null) { ret.Add(current.Value); current = current.Backward; } return ret; }
// 随机生成节点层数(抛硬币算法) privateintRandomLevel() { int level = 1; while (_random.NextDouble() < PROBABILITY && level < MAX_LEVEL) ++level; return level; }
for (int i = _level - 1; i >= 0; i--) { StringBuilder sb = new(); sb.Append($"Layer{i}\t"); SkipListNode current = _header; while (current != null) { sb.Append($"{current.Span[i]}\t"); if (current.Forward[i] != null) sb.Append(newstring('\t', current.Span[i] - 1)); else sb.Append(newstring('\t', current.Span[i])); current = current.Forward[i]; } Console.WriteLine(sb);
} var cur = _header; string o = "Data\t"; string s = "Score\t"; while (cur != null) { if (cur.Value == null) { o += "Head\t"; s += "Head\t"; } else { o += cur.Value.ToString() + '\t'; s += cur.Score.ToString() + '\t'; } cur = cur.Forward[0]; } Console.WriteLine(); Console.WriteLine(o); Console.WriteLine(s); } }
代码说明
更新跨度的代码:
1 2 3 4 5 6
for (int i = 0; i < newLevel; i++) { ... newNode.Span[i] = update[i].Span[i] - (rank[0] - rank[i]); update[i].Span[i] = (rank[0] - rank[i]) + 1; }
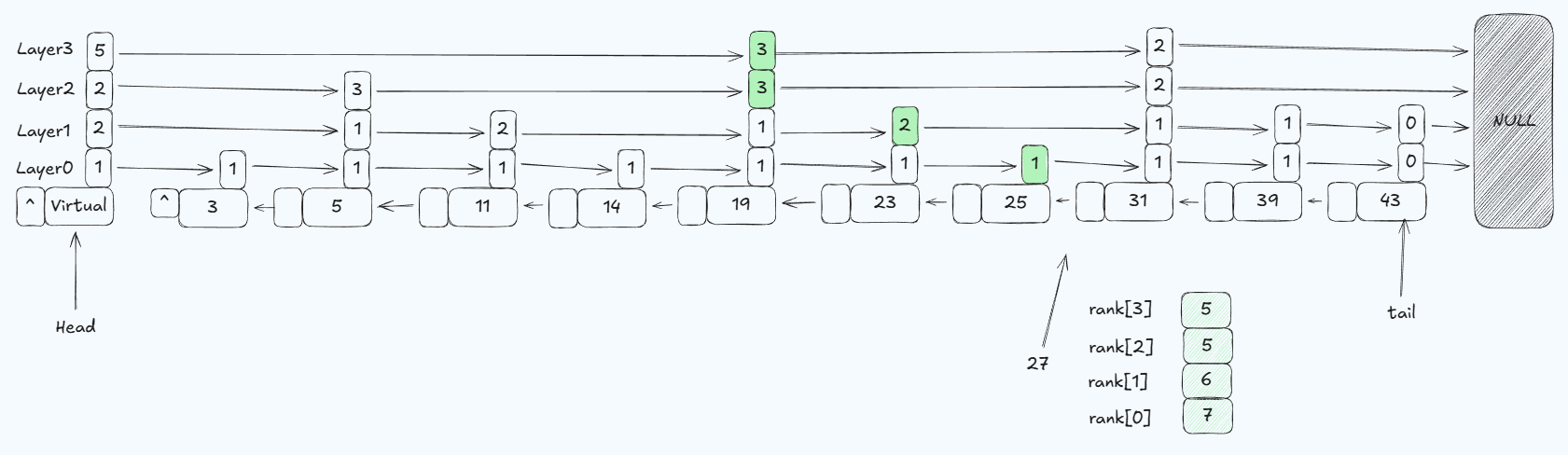
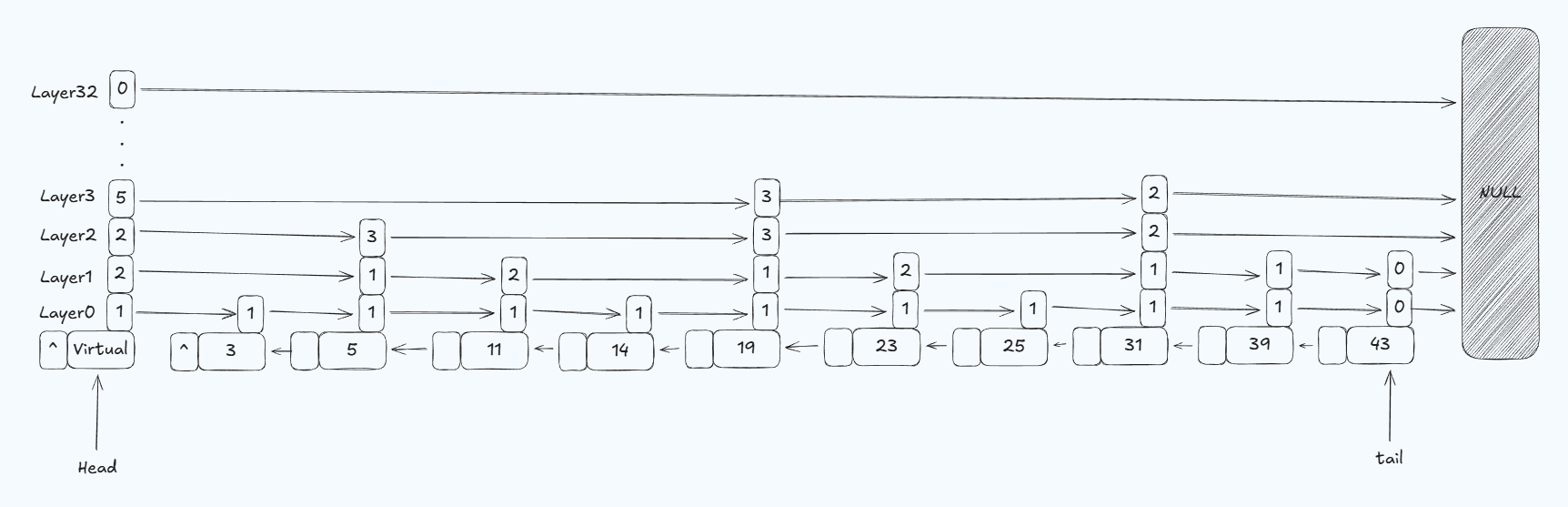 跳跃表的每个节点拥有一个前序指针和多层后继指针。每层后继指针都独立成链,每个节点在插入时,都会按照概率分配给它多少层后继指针(至少一层)。类似抛硬币,落到正面,就给它加一层后继指针,然后继续抛硬币;落到反面就结束。当然,硬币正面的概率不一定是50%(实际有论文提出,包括业内经验来看,25%的概率是对性能和内存占用权衡后的得到的较优选择)。实际上,作者最初考虑过确定性跳表,即第0层是全连接,第1层是隔1个连接,第2层是隔3个连接…但是这样会导致插入和删除需要进行大量调整,复杂度变高,从而引入随机性,不仅简化了插入和删除的操作,并且统计上仍然是接近二分的结构。
跳跃表的每个节点拥有一个前序指针和多层后继指针。每层后继指针都独立成链,每个节点在插入时,都会按照概率分配给它多少层后继指针(至少一层)。类似抛硬币,落到正面,就给它加一层后继指针,然后继续抛硬币;落到反面就结束。当然,硬币正面的概率不一定是50%(实际有论文提出,包括业内经验来看,25%的概率是对性能和内存占用权衡后的得到的较优选择)。实际上,作者最初考虑过确定性跳表,即第0层是全连接,第1层是隔1个连接,第2层是隔3个连接…但是这样会导致插入和删除需要进行大量调整,复杂度变高,从而引入随机性,不仅简化了插入和删除的操作,并且统计上仍然是接近二分的结构。