轻量级模块仓库与事件系统设计
轻量级模块仓库与事件系统设计
设计目标
在 Unity 项目中提供一套轻量级的全局模块仓库和事件系统。模块的生命周期与游戏进程一致:启动后按需创建或显式注册,在游戏运行期间持续存活,并在游戏关闭时统一释放。
业务代码通过以下接口使用系统:
1 | ModuleRepository.GetOrCreate<T>(); |
在 Unity 项目中提供一套轻量级的全局模块仓库和事件系统。模块的生命周期与游戏进程一致:启动后按需创建或显式注册,在游戏运行期间持续存活,并在游戏关闭时统一释放。
业务代码通过以下接口使用系统:
1 | ModuleRepository.GetOrCreate<T>(); |
这份笔是我学习Github开源项目Arch ECS后的学习代码,通过断点调试 + 与AI交流完成碎片化记录,最终再交由AI整合完成。主要内容包含Archetype ECS结构学习,以及一些项目里用到的技巧总结。
在学习过程中发现了两处问题,一处是BitSet的Any处包含冗余的循环代码;一处是CommandBuffer部分的SparseSet里创建SparseArray时传参错误。目前已经提交了PR。
Arch 的核心数据关系可以先记成这张图:
简单写一个迭代器方法。
1 | void Start() |
上面的迭代器方法,在内部,编译器会生成一个匿名类,代码如下:
SparseSet(稀疏集) 是一种专为有界整数 ID设计的高性能集合数据结构,核心优势是插入、删除、查询、清空均为 O (1) 时间复杂度,且遍历高效、缓存友好。它通过稀疏数组(sparse)+ 密集数组(dense)+ 元素计数(n) 实现,广泛用于游戏引擎(如 ECS)、编译器、图算法等场景。
SparseSet 由三部分组成:
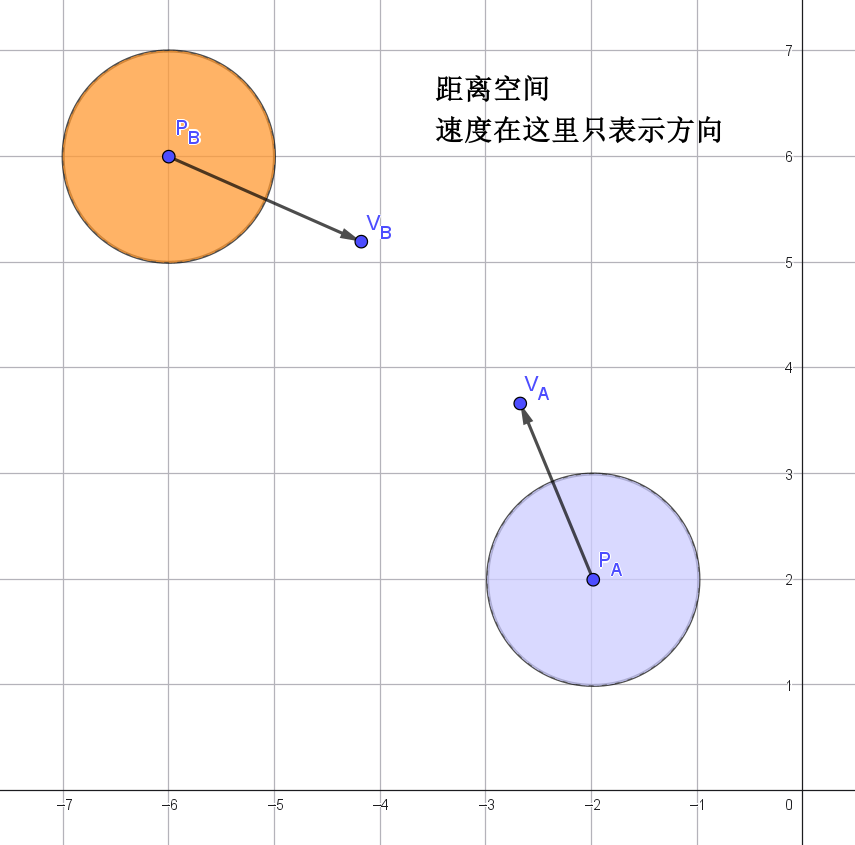
ORCA避障算法,出自2011年的一篇论文《Optimal Reciprocal Collision Avoidance》。该算法的思想不算复杂,但实现上有很多细节需要注意。网上已有很多对该算法的讲解,但是大多都比较粗略,很多细节并未详解,缺少很多图解来帮助理解,因此本文着重通过图解的形式,辅以文字,来剖析该算法的思想,并对关键源码进行解释。
如图所示,假设存在A、B两个对象,它们以图中的速度(速度是向量,包含方向和模大小)运动。
不论碰撞体本身是圆形、OBB、多边形,都可以获得顶点集合的minPoint: (minX, minZ)和maxPoint: (maxX, maxZ),得到最大外接矩形也就是AABB,将所有待检测对象的AABB投影到对应的轴上。每个对象在每个轴上都会得到一个线段,两个不同对象的线段如果在某一个轴上没有交集,就证明一定不存在碰撞,反之,在所有轴上都存在交集,则这两个对象的AABB一定发生了碰撞,如果对象本身就是AABB那就检测完毕,否则需要进一步判断两个对象是否实际碰撞。
先从X轴开始,遍历每个对象,投影可以产生两个端点minValue, maxValue,将所有对象的投影端点都放入一个数组内,并按坐标从小到大进行排序。维护两个列表:活跃列表[]和重叠对列表[]。扫描线从左到右扫描这些端点。